应用场景
在节点集群部署环境,需要对大量的请求进行均匀分发以达到负载均衡的请求。
如果是简单的对节点数量进行取模映射,当增删节点的时候,原有的映射结果,绝大部分会失效,拓展性太差。
此时就需要使用一致性 Hash 算法,减少在服务器数量变化的时候造成的数据迁移影响。
一致哈希 是一种特殊的哈希算法。在使用一致哈希算法后,哈希表槽位数(大小)的改变平均只需要 K/N 个关键字重新映射,其中 K 是关键字的数量,N 是槽位数量。然而在传统的哈希表中,添加或删除一个槽位的几乎需要对所有关键字进行重新映射。
原理
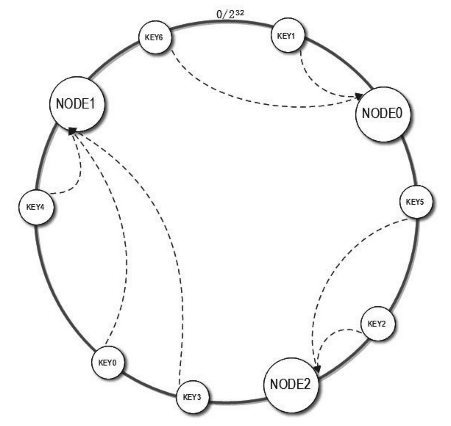
首先求出服务器(节点)的哈希值,并将其配置到 [0, 2^32-1] 的圆上。
然后采用同样的方法求出存储数据的键的哈希值,并映射到相同的圆上。
然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。
如果超过 2^32 仍然找不到服务器,就会保存到第一台服务器上。
如图所示,节点 Node0,Node1,Node2 ,如果数据被映射到 Node0 至 Node2 之间,那么数据将会最终对应到 Node2 节点上。
可能存在问题
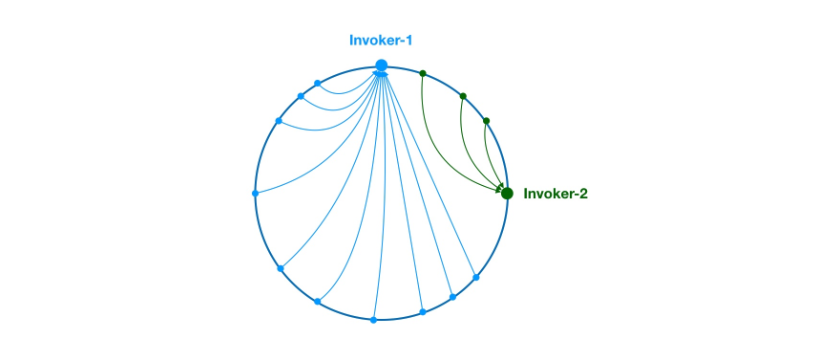
数据倾斜:服务节点太少,Hash 规则将大部分的请求映射到同一台服务器上,使得某一个节点压力大。如图所示,只有两个节点,绝大部分请求将会映射到 N1
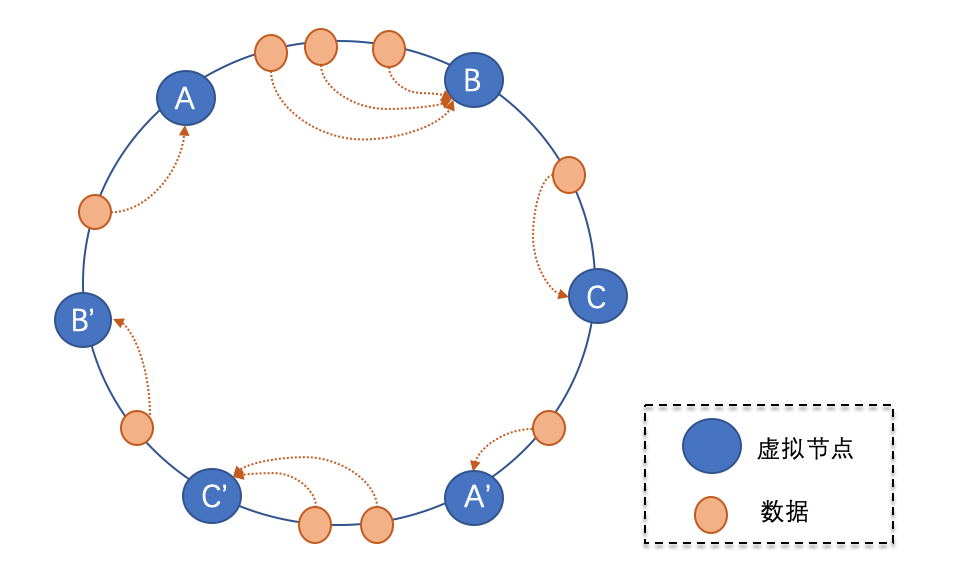
解决方案:将一个物理节点拆分为多个虚拟节点,并且同一个物理节点的虚拟节点尽量均匀分布在 Hash 环上。A 添加虚拟节点 A’,如果映射到 A’,那么最终会请求节点 A。
Java 实现(简单版本)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
| public class DemoA {
// 真实节点列表,假设有 5 个节点
public static String[] hosts = {"192.168.0.0",
"192.168.0.1",
"192.168.0.2",
"192.168.0.3",
"192.168.0.4",
"192.168.0.5"};
// 存储节点(真实+虚拟),并且能根据 key 排序
private static SortedMap<Integer,String> sortedMap = new TreeMap<>();
// 初始化加入节点,虚拟节点根据真实节点构建
static {
for (String ip:hosts) {
sortedMap.put(getHash(ip),ip);
System.out.println(ip + ":" + getHash(ip));
for (int i = 0; i < 1000; i++) {
// 虚拟节点只是后面加上字符串,取的时候方便根据虚拟节点找到真实节点
sortedMap.put(getHash(ip + "&" + i),ip + "&" + i);
}
}
}
// 将字符串转为 int 类型,网上抄的方法
public static int getHash(String str){
final int p = 16777619;
int hash = (int) 2166136261L;
for (int i = 0; i < str.length(); i++)
hash = (hash ^ str.charAt(i)) * p;
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
// 如果算出来的值为负数则取其绝对值
if (hash < 0)
hash = Math.abs(hash);
return hash;
}
// 根据字符串获取对应节点
public static String get(String key){
// 数据映射到环的值 A
int hash = getHash(key);
String finalIP = "";
Integer i;
// tailMap 返回比 hash 值大的子 Map
SortedMap<Integer,String> map = sortedMap.tailMap(hash);
// 如果环内没有比 hash 值大的,那么返回环的第一个节点
if (subMap.isEmpty()){
i = sortedMap.firstKey();
finalIP = sortedMap.get(i);
}else {
// 返回子 Map 的第一个节点
i = subMap.firstKey();
finalIP = subMap.get(i);
}
// 如果是虚拟节点,那么找到其对应真实节点
if (finalIP.indexOf("&") > 0){
finalIP = finalIP.substring(0,finalIP.indexOf("&"));
}
return finalIP;
}
public static void main(String[] args) {
String[] key = {"tes1","测试","HASH"};
for (String s:key) {
System.out.println(s + " hash is:" + getHash(s) + " to:" + get(s));
}
}
}
|
博客参考
对一致性Hash算法,Java代码实现的深入研究
面试必备:什么是一致性Hash算法?
