
索引
索引是一种数据结构,可以帮助我们快速的进行数据的查找。InnoDB 存储引擎的默认索引实现为 B+ 树索引。
索引分类
普通索引(index):最基本的索引,没有任何约束限制。
唯一索引(unique):和普通索引类似,但是具有唯一性约束,允许有空值,一个表可以有多个唯一索引。
主键索引(primary key):特殊的唯一索引,不允许有空值,保证实体完整性,一个表只能有一个主键。
联合索引:将多个列组合在一起创建索引,可以覆盖多个列。(也叫复合索引,组合索引)
全文索引:主要用于查找文本中的关键字,并不是直接与索引中的值进行比较。fulltext 更像是一个搜索引擎,配合 match against 操作使用,而不是一般的 where 语句加 like。
索引实现
MyISAM 和 InnoDB 都使用 B+Tree 作为索引结构。
InnoDB 主索引叶子节点就是数据本身,数据表的主键作为索引的 key。InnoDB 辅助索引叶子节点保存的是主键值,如果需要找到数据得先找到主键值,然后再根据主键去寻找。
MyISAM 主索引叶子节点和辅助索引叶子节点一样,存放数据记录的地址,要找到该数据还需要去该地址寻找。
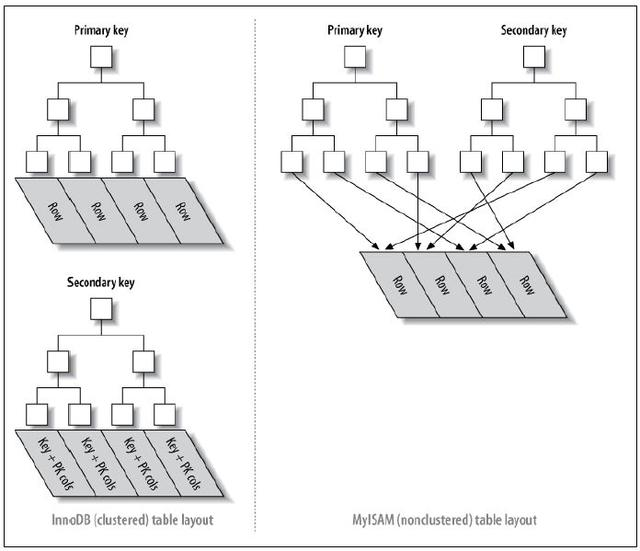
聚簇索引的叶节点就是数据节点,而非聚簇索引的叶节点仍然是索引节点,并保留一个链接指向对应数据块。
InnoDB 主键索引是 B+Tree 作为数据结构,而叶子节点存储的是元素值,满足聚簇索引定义。
explain 用法字段含义(分析是否有用到索引)
https://www.sunjs.com/article/detail/99169a7375834c158409036934f10fab.html
id 表示一个查询中各个子查询的执行顺序,id相同执行顺序由上至下。 id不同,id值越大优先级越高,越先被执行。id为 null 时表示一个结果集,不需要使用它查询,常出现在包含union等查询语句中。
select_type 表示查询中每个 select 子句的类型:
SIMPLE 不包含任何子查询或union等查询
PRIMARY 包含子查询最外层查询就显示为 PRIMARY
SUBQUERY 在select或 where字句中包含的查询
DERIVED from字句中包含的查询
UNION 出现在union后的查询语句中
UNION RESULT 从UNION中获取结果集
table 查询的数据表,当从衍生表中查数据时会显示 x ,表示对应的执行计划id
partitions 表分区、表创建的时候可以指定通过那个列进行表分区。
type 表示MySQL在表中找到所需行的方式,又称「访问类型」
ALL 扫描全表数据
index 遍历索引
range 索引范围查找
index_subquery 在子查询中使用 ref
unique_subquery 在子查询中使用 eq_ref
ref_or_null 对Null进行索引的优化的 ref
fulltext 使用全文索引
ref 使用非唯一索引查找数据
eq_ref 在join查询中使用PRIMARY KEYorUNIQUE NOT NULL索引关联。
possible_keys 可能使用的索引,但不一定被查询使用
key 显示MySQL在查询中实际使用的索引,若没有使用索引,显示为NULL; 查询中若使用了覆盖索引(覆盖索引:索引的数据覆盖了需要查询的所有数据),则该索引仅出现在key列表中
key_len 表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度
ref 表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
rows 返回估算的结果集数目,并不是一个准确的值。
filtered
Extra 包含不适合在其他列中显示但十分重要的额外信息
Using index 使用覆盖索引
Using where 使用了用where子句来过滤结果集
Using filesort 使用文件排序,使用非索引列进行排序时出现,非常消耗性能,尽量优化。
Using temporary 使用了临时表
查看索引
1 | mysql> show index from tblname; |
- Table:表的名称
- Non_unique:如果索引不能包括重复词,则为 0。如果可以,则为 1
- Key_name:索引的名称
- Seq_in_index:索引中的列序列号,从 1 开始
- Column_name:列名称
- Collation:列以什么方式存储在索引中。在 MySQL 中,有值 ‘A’(升序)或NULL(无分类)。
- Cardinality:索引中唯一值的数目的估计值。通过运行 ANALYZE TABLE 或 myisamchk -a 可以更新。基数根据被存储为整数的统计数据来计数,所以即使对于小型表,该值也没有必要是精确的。基数越大,当进行联合时, MySQL 使用该索引的机会就越大。
- Sub_part:如果列只是被部分地编入索引,则为被编入索引的字符的数目。如果整列被编入索引,则为 NULL。
- Packed:指示关键字如何被压缩。如果没有被压缩,则为 NULL。
- Null:如果列含有 NULL ,则含有 YES 。如果没有,则该列含有 NO。
- Index_type:用过的索引方法(BTREE, FULLTEXT, HASH, RTREE)。
- Comment:更多评注。
索引失效情况
% 开头的 like 模糊匹配
or 前后语句没有同时使用索引
数据类型出现隐式转化(字符串列查询没有使用引号)
索引列进行运算
建索引几个原则
最左前缀匹配原则,mysql 会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配。比如建立 (a,b,c,d) 联合索引,查询 a=1 and b=2 and c>3 and d = 4,d 将用不到索引
= 和 in 可以乱序,查询优化器会转化为索引可识别的形式
频繁作为查询条件的字段应该作为索引,区分度低的列作为索引即使查询频繁也不适合作为索引。
索引列不能参与计算,因为 B+ 树存储的是元素值,如果有计算就需要把所有元素先计算,然后进行比较查询。
进来拓展索引列,不要新建索引列。