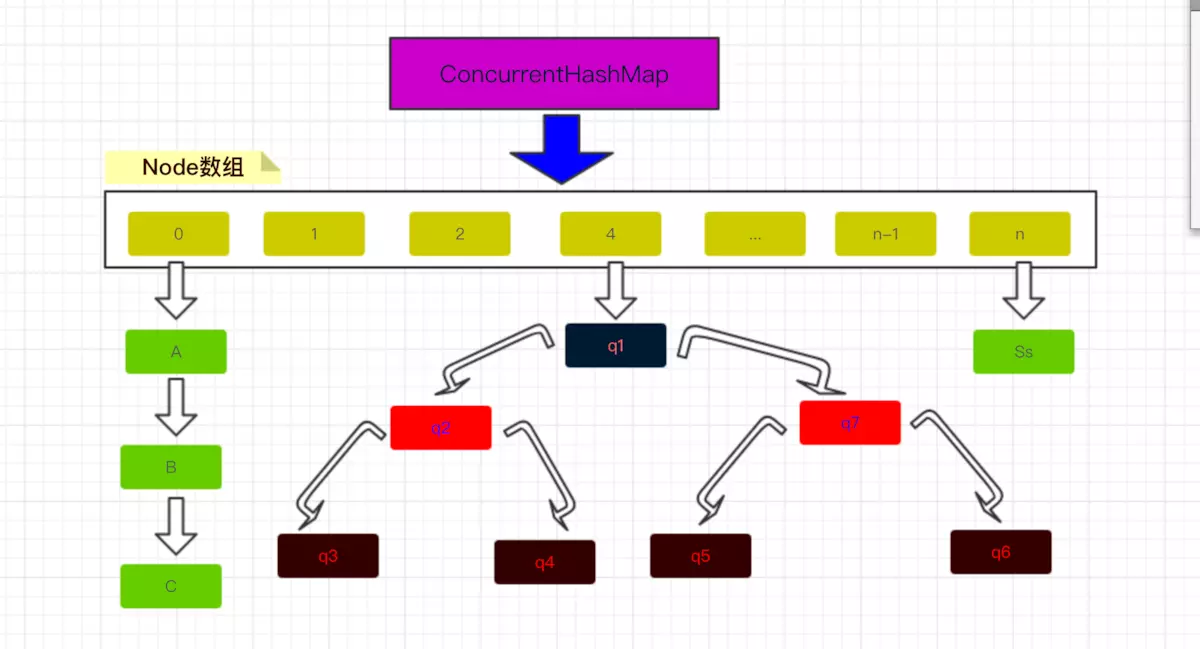
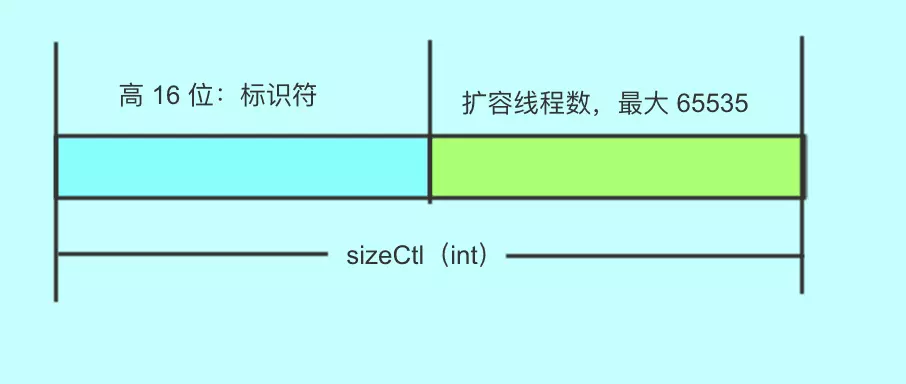
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
|
// 返回表长度 n 的标志位
static final int resizeStamp(int n) {
return Integer.numberOfLeadingZeros(n) | (1 << (RESIZE_STAMP_BITS - 1));
}
// 帮助扩容
final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) {
Node<K,V>[] nextTab; int sc;
// tab 不为 null,传进来的节点是 ForwardingNode,并且 ForwardingNode 下一个 tab 不为 null
if (tab != null && (f instanceof ForwardingNode) &&
(nextTab = ((ForwardingNode<K,V>)f).nextTable) != null) {
// 生成标志位 rs
int rs = resizeStamp(tab.length);
while (nextTab == nextTable && table == tab &&
(sc = sizeCtl) < 0) {
// 如果 sizeCtl 无符号右移 16 位与上面标志位不同
// 或者 sizeCtl == rs + 1 (扩容结束了,不再有线程进行扩容)
// 或者 sizeCtl == rs + 65535 (如果达到最大帮助线程的数量,即 65535)
// 或者转移下标正在调整 (扩容结束)
// 结束循环
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || transferIndex <= 0)
break;
// 以上情况不满足, sizeCtl++ ,增加一个线程进行扩容
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) {
// 复制或者移动 bins 里面的 Node 到新的 table
transfer(tab, nextTab);
break;
}
}
return nextTab;
}
return table;
}
// 移动或者复制 Node 到新的 table
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
// 计算单个线程允许处理的最少 table 桶首节点个数,不能小于 16
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // subdivide range
// 如果刚开始扩容,就初始化 nextTab
if (nextTab == null) { // initiating
try {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
nextTable = nextTab;
// transferIndex 指向最后一个桶,方便从后向前遍历
transferIndex = n;
}
int nextn = nextTab.length;
// fwd 作为标记,标记那些已经完成迁移的桶
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
boolean advance = true;
boolean finishing = false; // to ensure sweep before committing nextTab
// i 指向当前桶,bound 指向当前线程需要处理的桶结点的区间下限
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
while (advance) {
int nextIndex, nextBound;
if (--i >= bound || finishing)
advance = false;
// transferIndex 本来指向最后一个桶,小于等于 0 说明处理完成
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
// 更新 transferIndex,处理的桶区间为 (nextBound,nextIndex)
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
// 当前线程任务处理完成
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
if (finishing) {
nextTable = null;
table = nextTab;
sizeCtl = (n << 1) - (n >>> 1);
return;
}
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
finishing = advance = true;
i = n; // recheck before commit
}
}
// 待迁移的桶为 null,在此位置添加 ForwardingNode 标记该桶已经处理过
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
// 该桶已经处理过
else if ((fh = f.hash) == MOVED)
advance = true; // already processed
else {
// 锁住该桶
synchronized (f) {
// 再判断下桶有没有发生变化
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;
if (fh >= 0) {
int runBit = fh & n;
Node<K,V> lastRun = f;
// 整个 for 循环为了找到整个桶中最后连续的 fh & n 不变的结点
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
// 如果 fh&n 不变的链表的 runbit 都是 0,则 nextTab[i] 内元素 ln 前逆序,ln 及其之后顺序
// 否则,nextTab[i+n]内元素全部相对原table逆序
// 这是通过一个节点一个节点的往 nextTab 添加
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
// 把两条链表整体迁移到 nextTab 中
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
// 将原桶标识位已经处理
setTabAt(tab, i, fwd);
advance = true;
}
// 红黑树的复制算法
else if (f instanceof TreeBin) {
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
for (Node<K,V> e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K,V>(hi) : t;
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
}
}
}
}
}
|