
确定垃圾
引用计数:给对象中添加一个引用计数器,每当有一个地方引用它,计数器就加 1;当引用失效,计数器就减 1;任何时候计数器为 0 的对象就是不可能再被使用的。存在对象之间相互循环引用的问题。
根搜索:如果在“GC roots”和一个对象之间没有可达路径,则称该对象是不可达的。要注意的是,不可达对象不等价于可回收对象,不可达对象变为可回收对象至少要经过两次标记过程。两次标记后仍然是可回收对象,则将面临回收。
Java 四种引用类型:
强引用:把一个对象赋给一个引用变量,这个引用变量就是一个强引用
软引用:用 SoftReference 类来实现,对于只有软引用的对象来说,当系统内存足够时它不会被回收,当系统内存空间不足时它会被回收。软引用通常用在对内存敏感的程序中。
弱引用:用 WeakReference 类来实现,它比软引用的生存期更短,对于只有弱引用的对象来说,只要垃圾回收机制一运行,不管 JVM 的内存空间是否足够,总会回收该对象占用的内存。
虚引用:PhantomReference 类来实现,它不能单独使用,必须和引用队列联合使用。虚引用的主要作用是跟踪对象被垃圾回收的状态。
垃圾回收算法
标记-清除:标记需要回收的对象然后统一回收。效率低、碎片多
复制: 类似 eden、survivor 将存活的对象复制到另外一块区。
标记-整理:结合标记-清除、复制。标记后不是清理对象,而是将存活对象移向内存的一端。然后清除端边界外的对象。
分代收集:主流垃圾回收算法,根据对象存活周期不同分配到不同区域。新生代中,每次收集都会有大量对象死去,所以可以选择复制算法,只需要付出少量对象的复制成本就可以完成每次垃圾收集。而老年代的对象存活几率是比较高的,而且没有额外的空间对它进行分配担保,所以我们必须选择“标记-清除”或“标记-整理”算法进行垃圾收集。
分区收集:G1
垃圾回收器
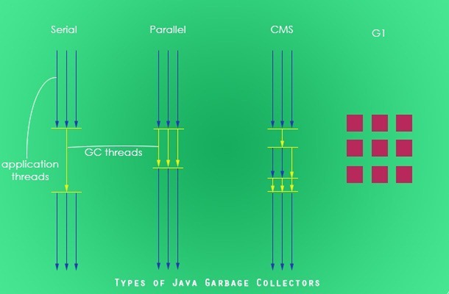
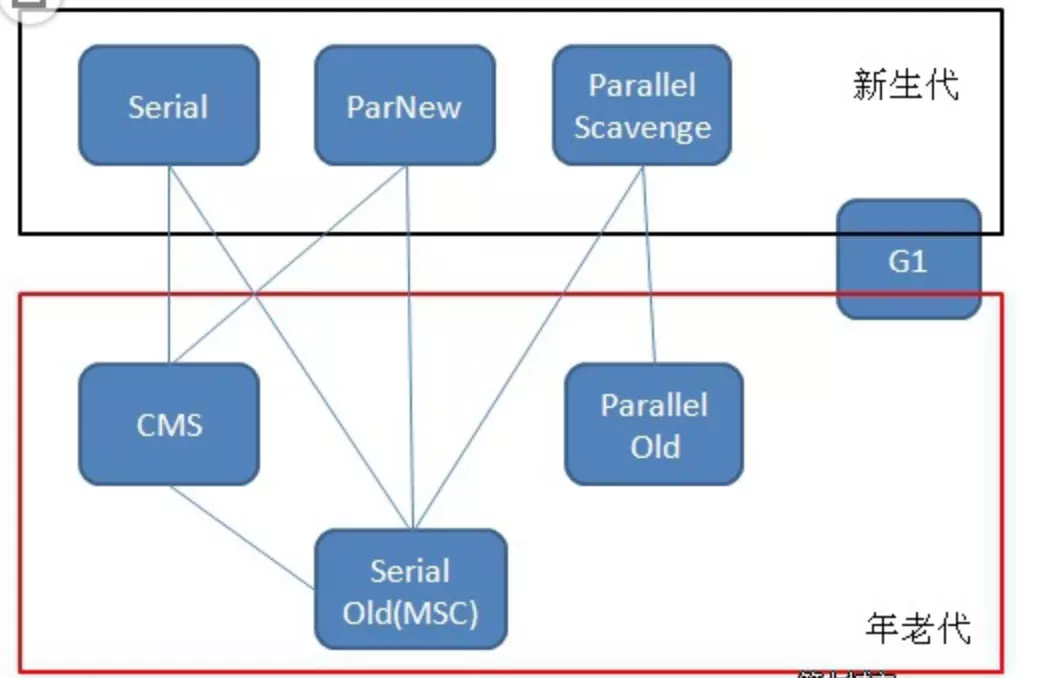
Serial :简单而高效,单线程,是 Java 虚拟机运行在 Client 模式下默认的新生代垃圾收集器,新生代采用复制算法,老年代采用标记-整理算法。
ParNew:Serial 的多线程版本,多个线程并发进行垃圾回收,其它与 Serial 一样。它是许多运行在 Server 模式下的虚拟机的首要选择,除了 Serial 收集器外,只有它能与 CMS 收集器(真正意义上的并发收集器,后面会介绍到)配合工作。
并行(Parallel) :指多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态。
并发(Concurrent):指用户线程与垃圾收集线程同时执行(但不一定是并行,可能会交替执行),用户程序在继续运行,而垃圾收集器运行在另一个CPU上。
Parallel Scavenge:新生代垃圾收集器,同样使用复制算法,也是一个多线程的垃圾收集器,重点关注的是程序达到一个可控制的吞吐量,高吞吐量可以最高效率地利用 CPU 时间,尽快地完成程序的运算任务,主要适用于在后台运算而不需要太多交互的任务。自适应调节策略也是ParallelScavenge 收集器与 ParNew 收集器的一个重要区别。
吞吐量=运行用户代码时间/(运行用户代码时间+垃圾收集时间)
Serial Old:Serial 垃圾收集器年老代版本、标记-整理,它同样是一个单线程收集器。它主要有两大用途:一种用途是在 JDK1.5 以及以前的版本中与 Parallel Scavenge 收集器搭配使用,另一种用途是作为 CMS 收集器的后备方案。
Parallel Old:使用多线程和“标记-整理”算法。在注重吞吐量以及 CPU 资源的场合,都可以优先考虑 Parallel Scavenge 收集器和 Parallel Old 收集器。
CMS(Concurrent mark sweep)一种以获取最短回收停顿时间为目标的收集器,它而非常符合在注重用户体验的应用上使用。
运行过程:
初始标记:标记一下 GC Roots 能直接关联的对象,暂停其他线程、速度很快
并发标记:GC tracing 过程,与用户线程一起工作
重新标记:修改并发标记期间,程序运行改变标记的部分,暂停其他线程。
并发清除:与用户线程一起工作,清除标记的区域。
G1,标记-整理
并行与并发:G1 能充分利用 CPU、多核环境下的硬件优势,使用多个 CPU(CPU或者CPU核心)来缩短 Stop-The-World 停顿时间。部分其他收集器原本需要停顿 Java 线程执行的 GC 动作,G1 收集器仍然可以通过并发的方式让 java 程序继续执行。
分代收集:虽然 G1 可以不需要其他收集器配合就能独立管理整个GC堆,但是还是保留了分代的概念。
空间整合:与 CMS 的“标记–清理”算法不同,G1 从整体来看是基于“标记整理”算法实现的收集器;从局部上来看是基于“复制”算法实现的。
可预测的停顿:这是 G1 相对于 CMS 的另一个大优势,降低停顿时间是 G1 和 CMS 共同的关注点,但 G1 除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为 M 毫秒的时间片段内。
博客参考
作者:SnailClimb
链接:https://juejin.im/post/5b85ea54e51d4538dd08f601
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。